Abstract
Registration of multiview point clouds conventionally relies on extensive pairwise matching to build a pose graph for global synchronization, which is computationally expensive and inherently ill-posed without holistic geometric constraints.
This paper proposes FUSER, the first feed-forward multiview registration transformer that jointly processes all scans in a unified, compact latent space to directly predict global poses without any pairwise estimation. To maintain tractability, FUSER encodes each scan into low-resolution superpoint features via a sparse 3D CNN that preserves absolute translation cues, and performs efficient intra- and inter-scan reasoning through a Geometric Alternating Attention module. Particularly, we transfer 2D attention priors from off-the-shelf foundation models to enhance 3D feature interaction and geometric consistency.
Building upon FUSER, we further introduce FUSER-DF, an SE(3)^N diffusion refinement framework to correct FUSER's estimates via denoising in the joint SE(3)^N space. FUSER acts as a surrogate multiview registration model to construct the denoiser, and a prior-conditioned SE(3)^N variational lower bound is derived for denoising supervision. Extensive experiments on 3DMatch, ScanNet and ArkitScenes demonstrate that our approach achieves the superior registration accuracy and outstanding computational efficiency.
Moving beyond the conventional “pairwise-then-global” paradigm, FUSER and its diffusion variant, FUSER-DF, achieve state-of-the-art performance with a dramatic runtime reduction from minutes to seconds.
Demos
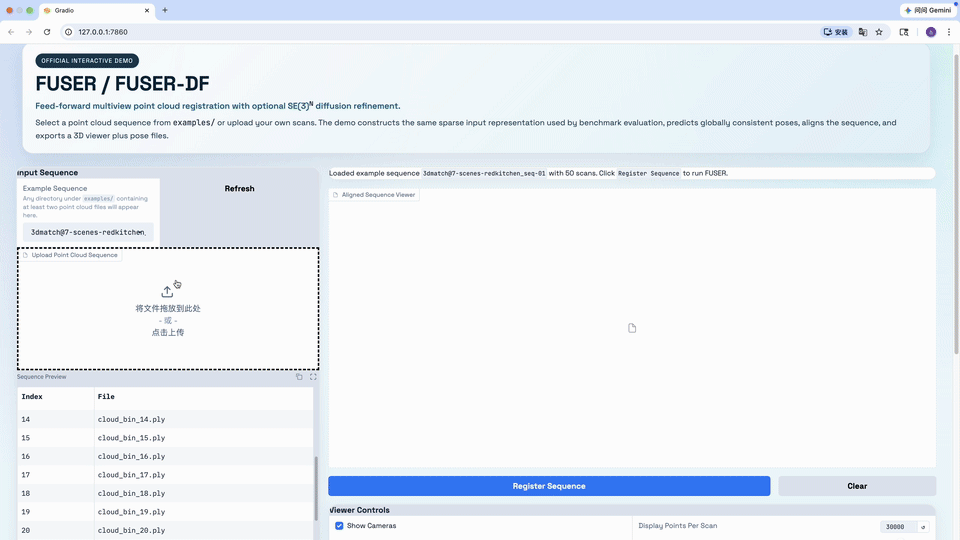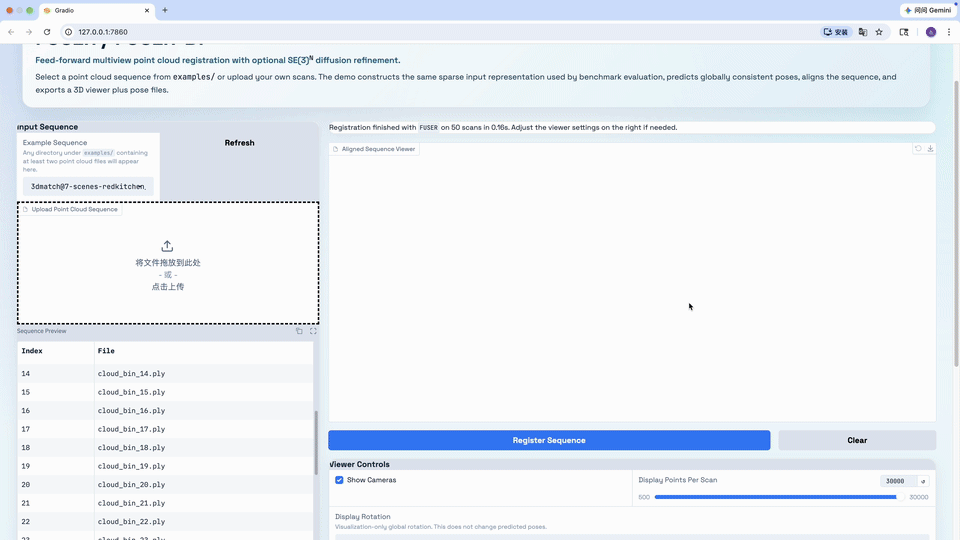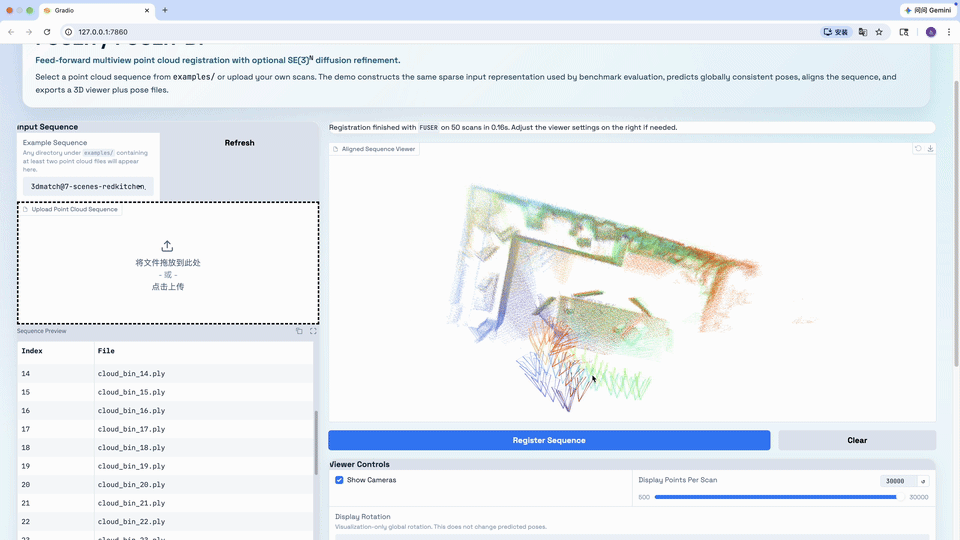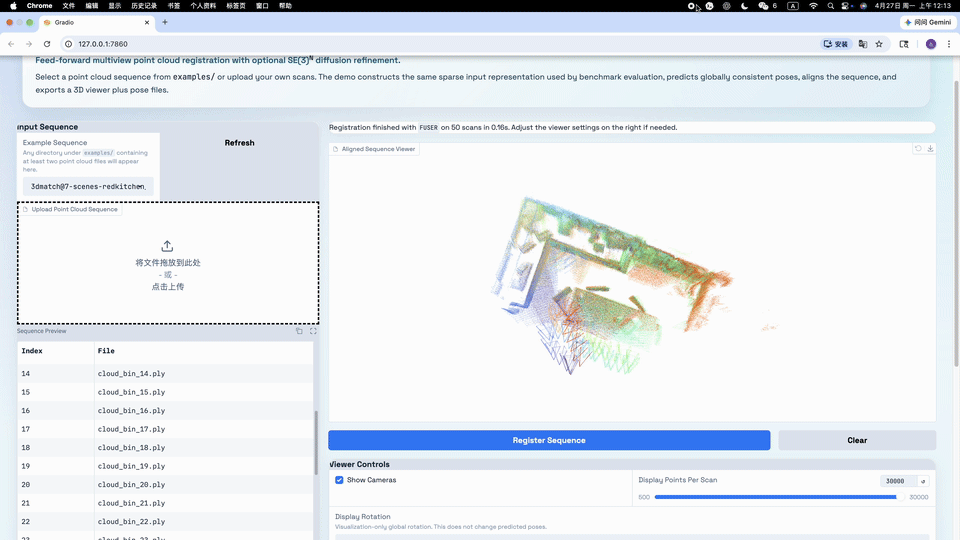
|

|